1. 基本概念与术语
1.1. 机器学习的类型
根据训练期间接受的监督数量和监督类型,可以将机器学习系统分为以下四个主要类别:有监督学习、无监督学习、半监督学习和强化学习
有监督学习(Supervised Learning)是当前机器学习的一种主流方式,但样本标记需要耗费大量人工成本,容易出现样本累积规模庞大,但标记不足的问题。
无监督学习(Unsupervised Learning)则是一种无须依赖标记样本的机器学习算法,聚类算法就是其中具有代表性的一种。
半监督学习
强化学习
1.2. 模型的泛化能力
机器学习模型学习到的概念在它处于学习的过程中时模型没有遇见过的样本时候的表现,模型的泛化能力越强,就越能说明这个模型表现越好。
- 欠拟合:训练集的预测值,与训练集的真实值有不少的误差,称之为欠拟合。
- 过拟合:训练集的预测值,完全贴合训练集的真实值,称之为过拟合。过拟合是在某一组训练集上表现得很好,但换一批数据进行预测结果就很不理想,泛化能力不行,不具有通用性。
1.3. 评价指标
我们以分类问题中的二元分类器为例。
将机器学习模型的预测与实际情况进行对比后,结果可以分为四种:TP、TN、FN和FP。每一种结果由两个字母组成,第一个字母为T或F,是 True 和 False 的首字母缩写,表示预测结果是否符合事实,模型猜得对不对。第二个字母为P或N,是 Positive 和 Negative 的首字母缩写,表示的是预测的结果。
1.3.1. 混淆矩阵
[!NOTE] 混淆矩阵(Confusion Matrix) 就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来,它是评判模型结果的指标,属于模型评估的一部分,是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
我们上面说了四种结果分类
如下所示:
TP——True Positive(真正),将正类预测为正类(正确肯定)
TN——True Negative(真负),将负类预测为负类(正确否定)
FP——False Positive(假正),将负类预测为正类 (错误肯定,误报)
FN——False Negative(假负),将正类预测为负类 (错误否定,漏报)
这四个指标呈现在一个表格中,就成了如下的这个矩阵:
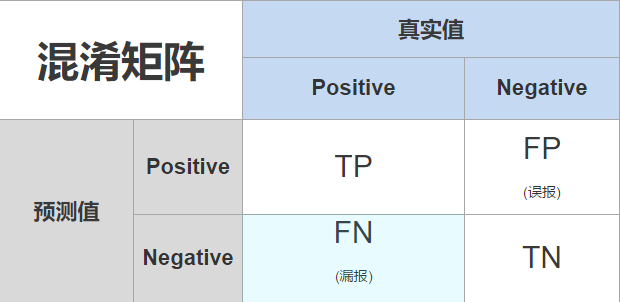
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小,我们顺着去看混淆矩阵中的指标。
1.3.2. 准确率(Accuracy)
准确率(Accuracy) 的计算方式为:
准确率(Accuracy)公式的含义是:模型猜对了的结果在全部结果中的占比,即正确预测的比率。
[!WARNING] 在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷,比如负样本很多时,一个会将样本全部判负的错误模型也能得到很高的准确率。
1.3.3. 精确率(Precision)
精确率(Precision),又叫查准率、精度,它的计算方式为:
TP是真正类的数量,FP是假正类的数量。
精确率(Precision)公式的含义是:表示被分为正例的示例中实际为正例的比例。
1.3.4. 召回率(Recall)
召回率(Recall),又叫查全率、灵敏度,它的计算方式为:
TP是真正类的数量,FN是假负类的数量。
召回率(Recall) 公式的含义是:衡量分类器对正例的识别能力,表示所有正例中被分对的比例
[!WARNING]
11111
1.3.5. F值(F-Measure)
F值(F-Measure),又称为F-Score。F值(F-Measure)是 精确率(Precision) 和 召回率(Recall) 的加权调和平均:
1.4. KaTex
1.5. TODO
梯度下降法(Gradient Descent):首先由梯度确定方向,当损失值比较大时,梯度会比较大,假设函数的参数更新幅度也会大一些,随着损失值慢慢变小,梯度也随之慢慢变小,假设函数的参数更新也就随之变小了。这就是采用梯度下降作为优化方法时,利用梯度调整假设函数的参数,最终使损失值取得最小值的过程。
每次迭代都使用全部样本的,称为批量梯度下降(Batch Gradient Descent);每次迭代只使用一个样本的,称为随机梯度下降(Stochastic Gradient Descent)。因为需要计算的样本小,随机梯度下降的迭代速度更快,但更容易陷入局部最优,而不能达到全局最优点